Step 3 · Harmonization
Harmonization is where BibexPy most strengthens the analytical validity of merged Scopus–WoS data: it resolves author identities, consolidates institution and country names, fills missing metadata from authoritative sources, and quantifies the resulting completeness.
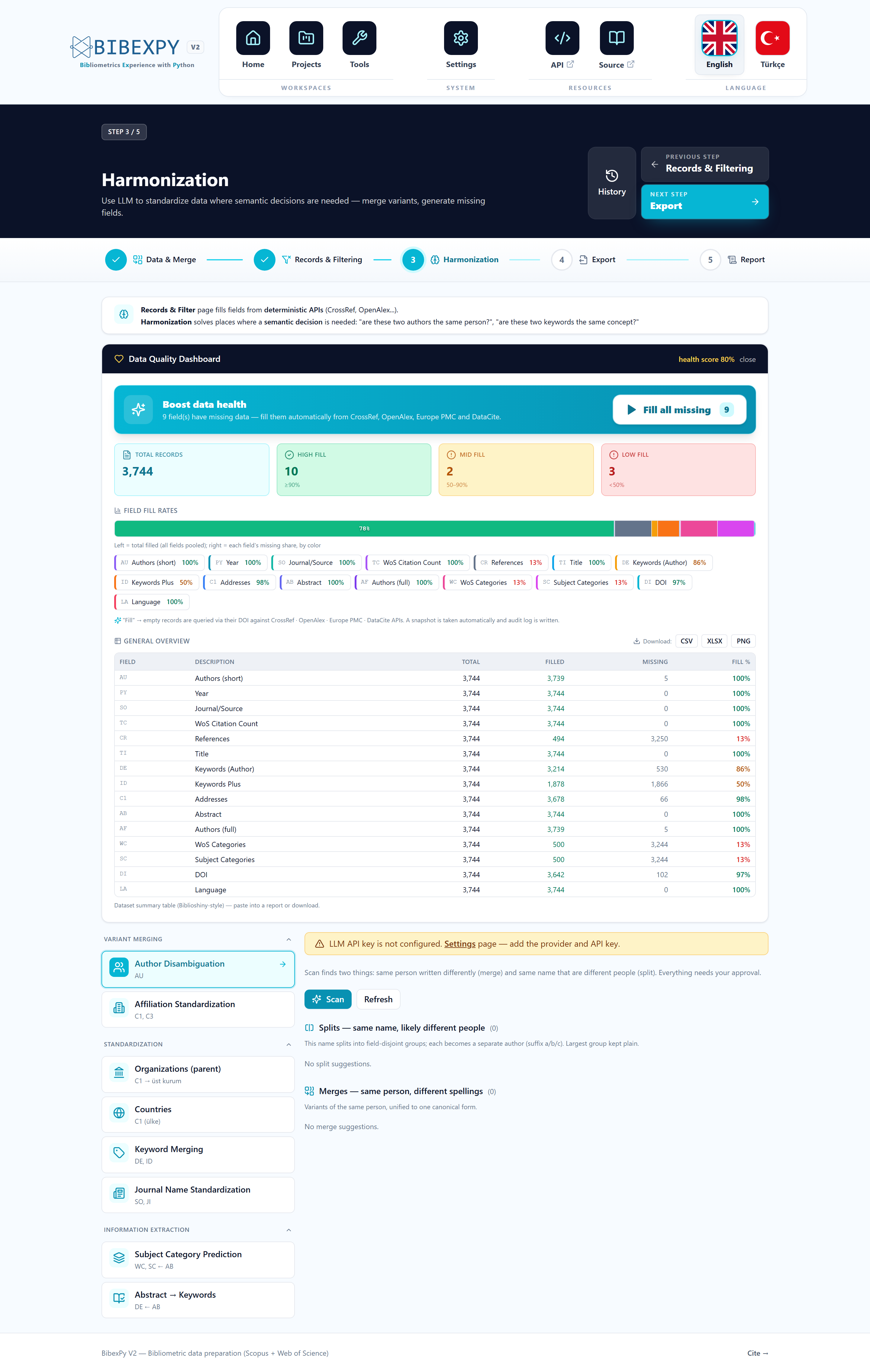
The four components
| Tool | What it fixes | Deep dive | | --- | --- | --- | | Author disambiguation | "J. Smith" vs "Smith, John" vs ORCID-confirmed identities | Read more | | Address harmonization | "Wuhan Univ" vs "Wuhan University" vs department-level variants; country spellings | Read more | | Metadata enrichment | Missing DOIs, abstracts, ORCIDs, categories — filled from 7 authoritative sources | Read more | | Quality dashboard | Quantifies completeness with a bibliometrically weighted health score | Read more |
Explainable, controlled, reversible
- Every operation runs on the same merged dataset with full, reversible logging.
- High-confidence decisions apply automatically; borderline cases route to a review queue where you approve or reject each one.
- A snapshot is taken before anything is applied — one click restores the previous state.
- Optional LLM assistance (for semantic decisions like merging name variants) is off by default, only touches user-approved cases, and never invents values.
Deterministic by default
Core transformations use rule-based logic and string/context similarity — not predictive ML models. Repeated runs produce identical results.
Suggested order
- Run the quality dashboard first to see which fields need attention.
- Run enrichment to fill missing metadata from external sources (improves disambiguation inputs too).
- Run author disambiguation, reviewing the borderline queue.
- Run organization & country harmonization last, then re-check the health score.