Filtering & Presets
Defining the study corpus is a decisive and often under-documented step in bibliometric research. BibexPy treats filtering as a transparent screening stage: criteria are explicit, evaluated against a live count, and saved for reuse.
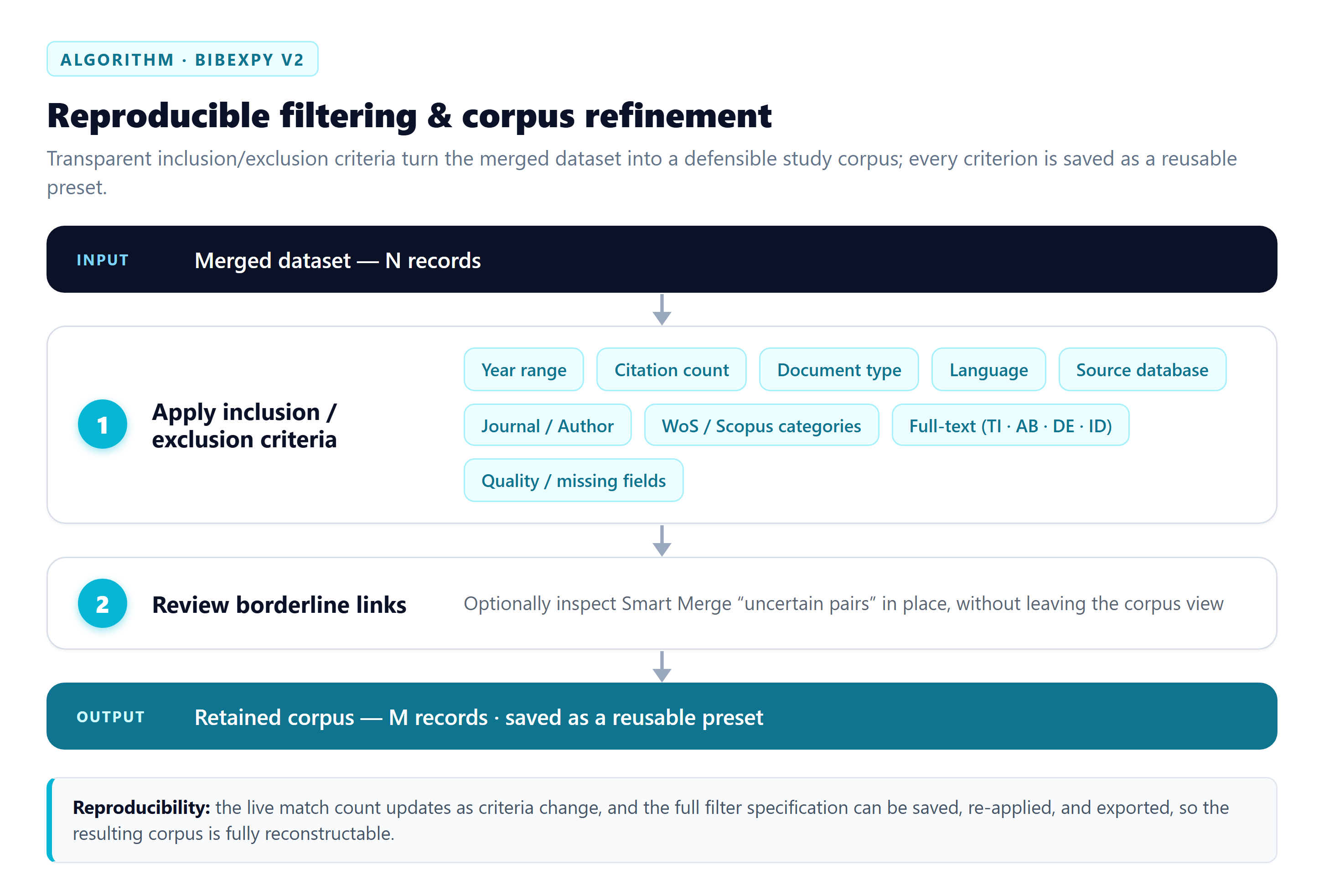
Criteria model
All criteria combine with AND semantics across dimensions; multi-select facets (e.g. document types) combine with OR within the dimension:
corpus = records
WHERE year BETWEEN 2015 AND 2024
AND doc_type IN ('Article', 'Review')
AND language = 'English'
AND (TI OR AB OR DE OR ID CONTAINS "machine learning")
AND has(DOI)
Live evaluation
The match count re-evaluates as you type — you see instantly how each criterion shrinks the corpus, which makes PRISMA-style flow numbers easy to extract.
Presets
- Save the full criterion set under a name (e.g.
core-2015-2024-en). - Re-apply it to any other analysis in the project — identical corpus definition, zero manual error.
- Export the preset for supplementary materials or a colleague.
Quality filters
Beyond content criteria, you can screen on field presence: require DOI, abstract, cited references, or exclude records missing affiliations — useful for tool-specific requirements (e.g. co-citation analysis needs CR).
Filters + export
The Export step can apply the active filter, so "the dataset we analyzed" and "the criteria we reported" are guaranteed to match.